This isn’t some sort of novel technique or anything of the sort, this is merely something I accidentally stumbled upon that sparked my interest. Mainly because of the fact that I’ve never seen this mentioned anywhere despite its errr… “ease of abuse”, where it can be applied that is.
Table of Contents
Well? Out with it!
When one thinks of directory enumeration, the first thing that comes to mind is usually brute-forcing. While that is a perfectly valid option, it’s got a few interesting quirks about it. The first being speed can vary from tool to tool and the other being results can be based on the wordlist supplied. Would be nice if there was something out there that could fetch a large number of directories (possibly all of them) all in the time it takes to write the syntax for something like gobuster. Well what if I told you there was?….well with one caveat: This technique will fail if the website doesn’t contain a sitemap.xml file, and not every website does. But for those that do, this technique is a great way to quickly amass a list of directories without having to wait for a directory fuzzing tool to go down a list. Not to mention, generate the amount of traffic a directory fuzzing tool generates if you care about that.
Sitemap? Never heard of it
sitemap.xml is a special file used by search engines to easily discover content on a website. Various known CMSs like WordPress (not only can we hope for a plugin that leads to RCE, we can also hope for sitemap.xml too!) automatically generate these sitemap files to make it easier for search engines to locate content on their pages. After all, who doesn’t want their blog on the first page of google results? Because let’s be honest here, no one goes past that first page.
Abusing Sitemap
So how can we abuse this? Well if Google can map a website using this file, what’s stopping us from doing the same thing? We can surmise that the sitemap.xml file contains….well, XML. A quick google search lead me here. Cool, there’s a .NET namespace for the parsing of XML files, we can use this.

Looks like the file does indeed contain XML, no surprises there. Casting the contents of the file as an XML object (thanks .NET) did something rather interesting and could definitely work in our favor.

Now we have an XML object we can (hopefully) easily extract information from. A little messing around with the properties eventually lead me to this nice one-liner:

Cool. Now we have a one-liner that will list all XML files contained in the base sitemap.xml. From what I’ve noticed, many CMSs use this method of nested sitemap files to organize content. Since these files are all in a nice list, let’s see if we can iterate through each of these files and extract the directories within.

Adding a ForEach-Object, we’re able to loop through each of the returned XML files and extract the URLs contained within. We can automate this. Since the one-liner has already been crafted, we’ll just have to add a bit of logic and redirect the output and we’ll have ourselves a quick script that can easily extract all URLs from a website containing a sitemap.
Introducing (and the making of) DirSnipe
I noticed quite a few folks on the Twitters asking about how to write tools and whatnot. I like to write semi-useless (only half the time..I think) tools when I get bored so I might as well throw my hat in the ring. The way I see it, toolsmithing is more of a mindset than anything, or maybe the years of coding have finally gotten to me and hardwired me to automate-all-the-things…who knows.
DirSnipe was originally a late-night project that I wrote up first in python and then ported over to PowerShell which reached out to robots.txt of a website and returned all the directories with the Disallow tag. After my antics with sitemap.xml, I figured I’d add the feature to crawl the sitemap if one is found and the option is passed.
Since the core “engine” of this feature has already been created, all that’s left is writing some logic around it to control the output.
[XML](Invoke-WebRequest grimmie.net/sitemap.xml) |select -expand sitemapindex |select -expand sitemap | select -expand loc | ForEach-Object { [XML](Invoke-WebRequest $_) | select -expand urlset | select -expand url | select -expand loc}This entire one-liner is generic with the exception of the following line:
Invoke-WebRequest grimmie.net/sitemap.xmlThis can easily be made entirely generic by asking the user to input a domain, append /sitemap.xml to the end, and put it into this one-liner. That would look something like this
[string]$site = Read-Host "Enter site: "
[XML](Invoke-WebRequest $site/sitemap.xml) |select -expand sitemapindex |select -expand sitemap | select -expand loc | ForEach-Object { [XML](Invoke-WebRequest $_) | select -expand urlset | select -expand url | select -expand loc}A rather simple addition, but it does the trick. I did something a little different and instead incorporated the previous code which reached out and scraped robots.txt.
V1
The initial version of the script had an empty string array initialized at the beginning and then a function that would parse out the directories and add them to the array. I then created another function to iterate through that array and append the directories to the input given by the user. That version looked something like this:
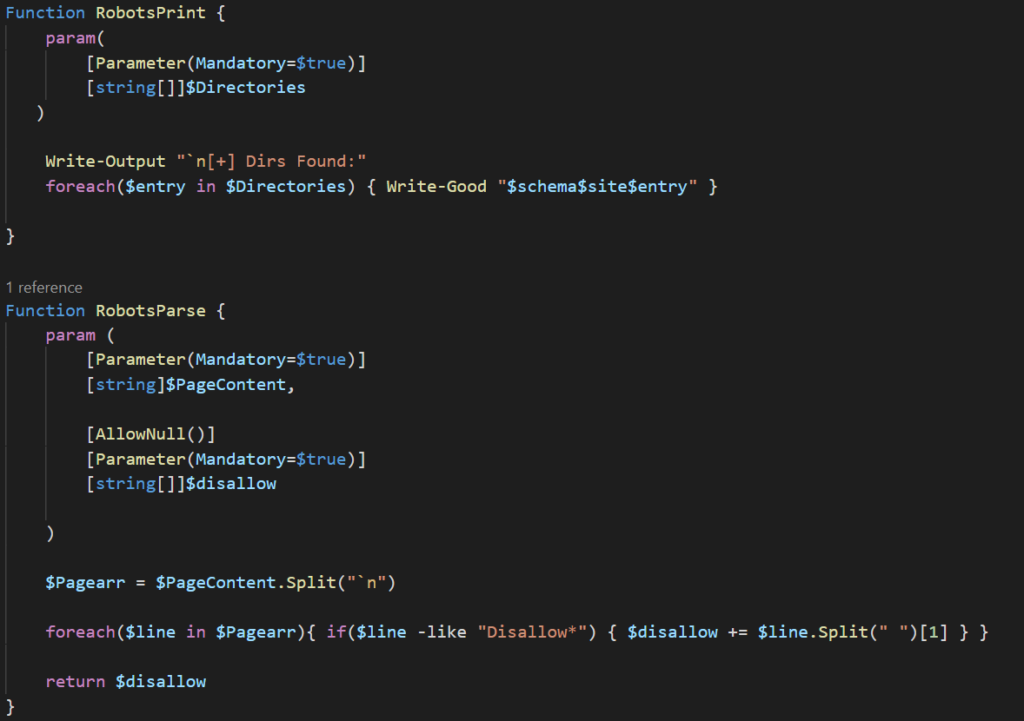
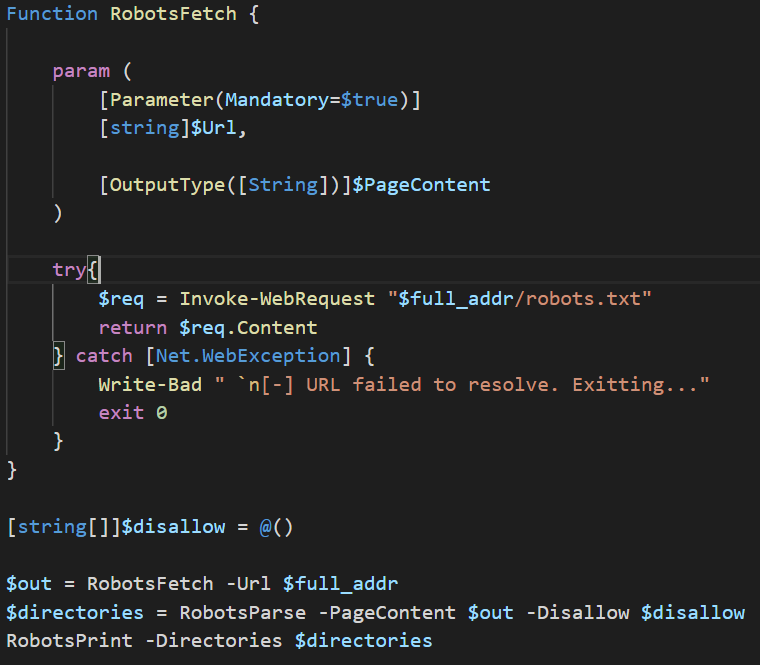
Let’s take a look at this code and see how we can expand upon what there already is. This snippet contains 3 functions, with each serving a specific task. It’s generally good practice to have functions built to one specific thing (much like the idea that every cmdlet has a single purpose in mind). This makes the code both easier to read and makes code reuse simple should you ever want to complete that task anywhere else. The three functions are as follows:
- RobotsPrint – iterates through array containing disallow entries and prints to console
- RobotsParse – extracts disallow entries from a robots.txt file and appends them to an array
- RobotsFetch – fetches and returns the contents of a robots.txt file
The last 4 line is where the code is actually doing something. We start by initializing the empty array (to be fair the RobotsParse can return a string array without having to pass it an empty one, that’s just how my brain works and it made sense at the time. Isn’t necessary, but I like it being there). The next line uses stores the contents of the robots.txt file and stores it in the $out variable (the $full_addr is taken from user input). The contents of the file are then passed to RobotsParse along with the empty array and return the passed array containing all disallow entries into the $directories string array. The final line takes that string array and iterates through printing each entry to the console.
Expanding Upon What We Already Have
So how can we expand upon what is already here to include sitemap crawling? Well, we can create another empty array for sitemaps (you’ll see why I’m putting this into an array and not a string later on, though the basic idea is to add more sitemaps to this array should anymore be discovered) and have the RobotsParse function add a sitemap entry to this array if any are found in the robots.txt file (robots.txt not only tells search engines what not to look at, but also tells them where everything is if the site has a sitemap.xml). We can then create a new function called SitemapCrawl that takes that reaches out and extracts “sub sitemaps” from the one found in robots.txt and adds them to the array. It will then iterate through each XML file in the array and append all URLs found into a new array and return it. That function would look something like this:
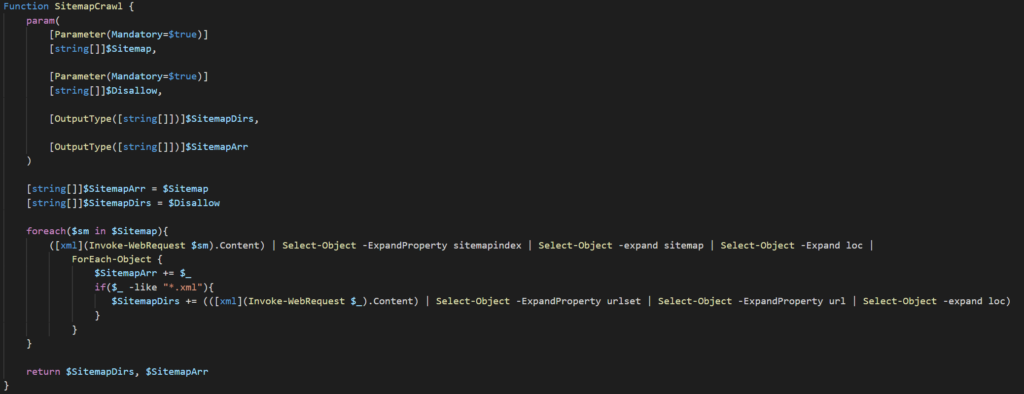
This function will take 2 inputs (the sitemap and disallow arrays previously populated respectively) and return 2 arrays(one containing all the sitemaps found and the other directories discovered). I find it fascinating how a function can return multiple values, but moving on. The two lines after that are initializing the return arrays and setting them to the arrays passed to the function. The reason for this is that we want the arrays to contain what was discovered previously as well as what will be scraped in the next few lines. The next chunk of code is where the arrays will be extended.

We’ll be using a foreach loop to iterate through the sitemap pulled from robots.txt and extract all XML files contained in the array. We’ll then use ForEach-Object to iterate through each link and check if the entry is an XML file. If the file is an XML, then add the entry to the $SitemapArr and then reach out to the link and add all URLs found to the $SitemapDirs array. The final line in this function returns both of these arrays.
Now we have a function that returns two arrays, one containing sitemaps found and the other containing URLs found respectively. That’s cool, but we’re going to want some way to view the contents of these arrays. To do this, we’ll create another function that will iterate through these arrays and print them to console. We’ll call this one SitemapCrawlPrint (so original, much wow).
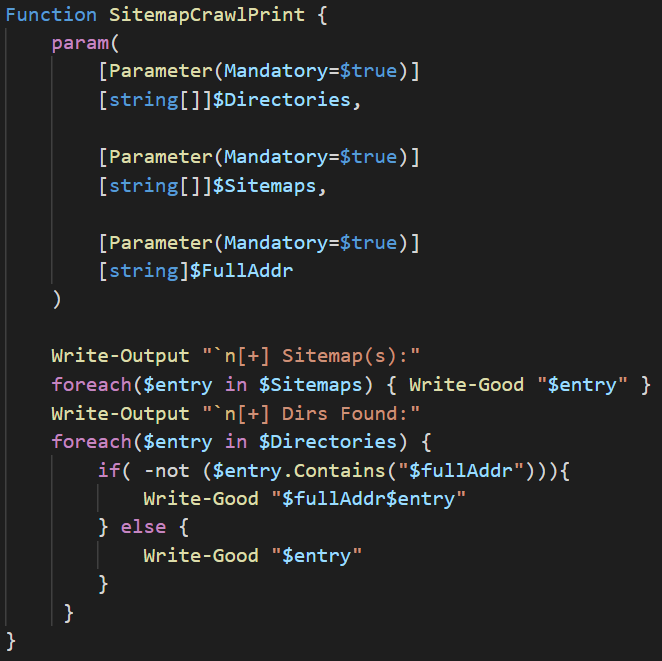
This function takes 3 arguments: the first 2 are the arrays returned from the SitemapCrawl function and the last one is the entire address of the site. The reason for that last one is because the $Directories array contains not only URLs fetched from sitemaps (these are full URLs), but also the directories from the disallow entries (these are only the directories so to return the entire path, we’ll append the $fullAddr variable to the element of the array if that element doesn’t contain the full URL path). Now let’s take a look at the actual code of the SitemapCrawlPrint function:
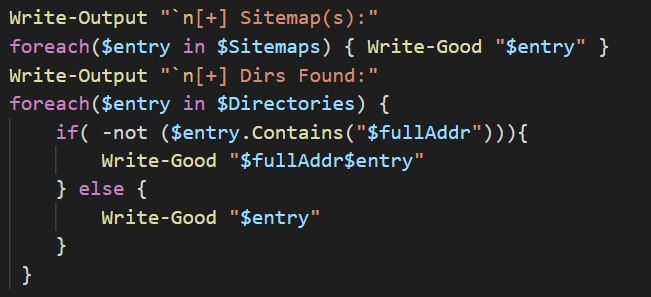
The function will use a foreach loop to iterate through the $Sitemaps array and print out all of the sitemaps discovered and then move onto the next foreach loop. This second loop will iterate through the $Directories and check whether or not the element contains the address path. If it does not, then it appends the path to the entry and prints it, and prints out the entry if it is a full URL path.
Now that we have all of the functions built, it’s time to bring it all together. I created a Function called Invoke-Scrape, added a few parameters to give a user the option to scrape sitemaps.xml or only robots.txt, and bundled all of the functions together.
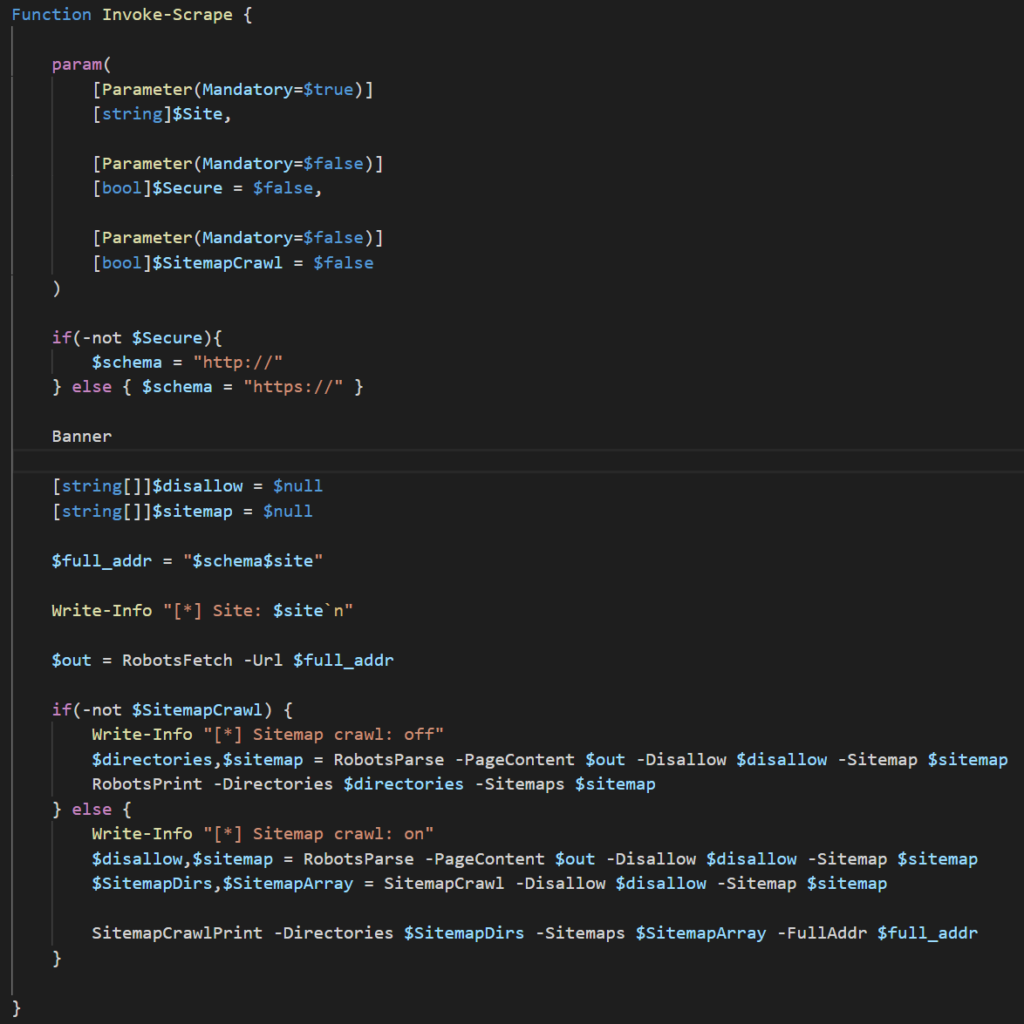
The Invoke-Scrape takes 3 parameters:
- Site – the website to target
- Secure – whether to use http or https (not entirely sure why I added this in, but hey why not)
- SitemapCrawl – whether to crawl sitemaps.xml or just return the sitemap entry in robots.txt
The function first checks if the $Secure parameter is set to true and determines which schema to use. The next few lines are creating the empty arrays to pass to the RobotsParse function, creating the $full_addr variable which stores the URL path, and printing the site to console (can’t forget the banner). The next line is where the script actually starts doing the stuff we want it to do. This line is reaching out to the robots.txt and puts the content into the $out variable which will be used later. The main chunk is what follows:
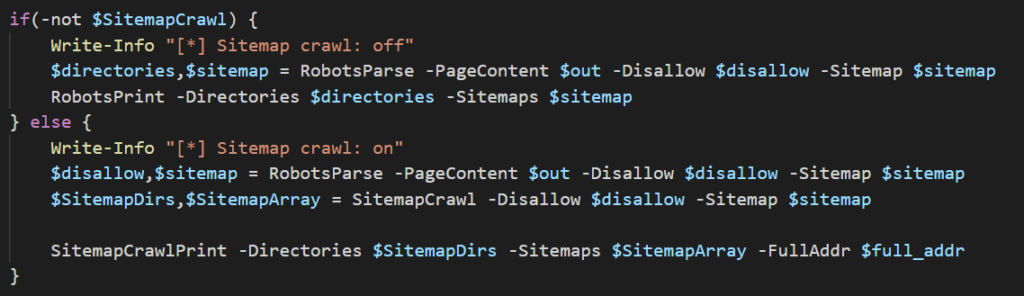
We’re first checking if the user wants to scrape the sitemap file(s) by looking at the $SitemapCrawl variable. If it’s set to false (it was either not provided or provided and passed $false) then it will do what the first version of this script did, if true then we move into the else block and scrape the sitemap. Let’s focus on this bit:

We’re first notifying the use the script is crawling sitemap. The next line is the same as the first block which uses the RobotsParse function and returns two arrays: $disallow and $sitemap. This is where the second block differs from the first. These arrays are then passed to SitemapCrawl which takes these arrays and expands them to include all of the URLs listed in sitemap files discovered and returns them. The final line passes the extended arrays and passes them to SitemapCrawlPrint, which will iterate through and print the contents of the array to the console.
Invoking (see what I did there…yeah I’m not apologizing for that) the function would look something like this:
# "importing" the script into current PowerShell process
. .\DirSnipe.ps1
Invoke-Scrape -Site grimmie.net -Secure $true -SitemapCrawl $trueClosing
I’ve found the process that works for me is something along the lines of
- Write out the process for how it’ll work
- Come up with a quick PoC to build around
- Write out a function for each action
- Bring it all together
- Clean-up code / housekeeping stuffs
This tool (if you can even call it that) might not be anything crazy, but I figured it would serve as a well enough example to go through my thought process when writing up tools/scripts. Scraping sitemaps is a perfectly valid option to amass directories in a short time if the option is there. I hope this post helped all y’all out there wondering how to go about the toolsmithing process and taught you a new way to perform directory enumeration.